今天写 Java 读文件时遇到编码问题,搜索了一晚上终于搞懂了这块问题。下面记录一下自己的笔记。
一、问题:
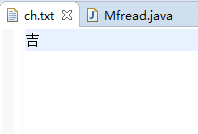
今天用 Java 写了一个读文件的,我用 eclipse 新建一个 utf-8 无 bom 编码的 txt 文件,叫做 ch.txt, 只写一个汉字: 吉, 完成后内容:
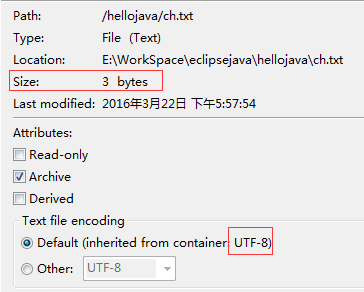
然后右击查看文件的属性:
读文件的代码为:
1 | package com.jiyiren.fileio; |
输出结果为:
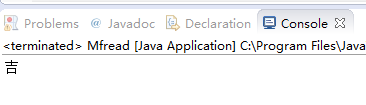
上面的代码与结果完全正确,那问题是什么呢?我们都知道 Java 中的 char 是 2 个字节,但是我们文件里保存的那个中文为 3 字节,读文件时我们也只用
1 | char c=new char[1] |
一个 char 类型读,但是结果为什么正确呢?java 中的 char 类型是Unicode 型的 2 个字节又是什么意思?文件保存的 utf-8格式与 Unicode 有什么关系呢? 下面我就讲下我的理解。
二、Unicode 编码
Unicode 编码的出现是为了解决世界上各种不同字符编码不一致的问题的,因为互联网的兴起,迫切需要这种统一世界上所有字符的编码。Unicode 当然是一个很大的集合,现在的规模可以容纳 100 多万个符号,每个符号的编码都不一样,比如:U+0639 表示阿拉伯字母 Ain,U+0041 表示英语的大写字母 A,U+4E25 表示汉字 “严”。
Unicode 编码以二进制代码格式规定了符号的唯一标识,它是一个符号集,它仅仅是给世界上各个字符规定了编码,但是它没有规定标识这些字母的二进制该如何存储。比如有的字符用 1 个字节就可以标识,但是有的字符要4个字节标识,如果都用4个字节标识每一个字符,那将会造成巨大的存储浪费,但是不这样存储又能有什么更好的存储方法呢?UTF-8 存储方式应运而生。
三、UTF-8 ( 存储 ) 编码
我们所知道的 UTF-8 编码,实际上它并非规定了字符的编码方式 ( 字符编码是由 Unicode 规定的 ),它只是规定怎么存储 Unicode 编码好的字符二进制数据,因而 UTF-8 编码默认包含了 Unicode 编码,我们通常所说的 UTF-8,实际上就是 Unicode UTF-8 编码。
UTF-8 是 Unicode 实现存储编码的一种方式,它最大的特点就是它是一种变长的编码方式。它可以使用 1~4 个字节表示一个符号,根据不同的符号而变化字节长度,这也就解决了 Unicode 编码用 4 个字节存储而浪费存储资源的问题了。
UTF-8编码的规则:
- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英文字母,UTF-8 编码和 ASCII 码是相同的。
- 对于n字节的符号(n>1),第一个字节的前n位都设为1,第 n+1 位设为0,后面字节的前两位一律设为 10。剩下的所有没有提及的二进制位,全部为这个符号的 Unicode 码。
1 | Unicode符号范围 | UTF-8编码存储方式 |
根据上表,以UTF-8 编码,如果一个字节的二进制的第一位是0,则这个字节单独就是一个字符,如果第一位是1,则连续有多少个1就表示该字符占有多少个字节。
汉字的 Unicode 编码表可以查看:http://www.chi2ko.com/tool/CJK.htm 或者 Unicode官网 然后我以汉字 “吉” 为例,演示将 “吉” 以 UTF-8 方式存储 “吉” 的 Unicode 编码的过程。
“吉”的Unicode编码十六进制数为 5409, 对应的二进制为 0101 0100 0000 1001; 因为 5409 把前面的全为 0 的 2 字节省略了,我们把它补上就是 0000 5409, 现在根据上表的左边一栏,可以知道该数在第三行范围里,所以 “吉” 的 UTF-8 编码占 3 字节,我们直接将第三行的右边栏中的 x 号换成 “吉” 二进制就可以了,最后结果:11100101 10010000 10001001,这个就是 “吉” 字的 Unicode 的 UTF-8 编码的存储字节形式。
四、解决问题
讲了这么多问题一点没有提到啊,我们根据上面的UTF-8的存储过程可以知道,中文 “吉” 的 Unicode 编码为 5409, 不用 UTF-8 存储表示时,“吉” 应该只占用两个字节,也就是说 java 中的 char 是 2 个字节完全可以存储的,但是这个存储只能在内存中,而如果写入文件,必须用到编码,而我们用的是 UTF-8 编码,由上面的转换过程可以知道,中文 “吉” 字的 Unicode 码的 UTF-8 形式需要 3 个字节的,所以保存在文件里时文件所占用的存储空间为 3 byte, 到这里我想大家应该都明白了为什么存在文件中的字是3个字节,而读出来的竟然用 char 就可以存储了的原因了。
Java 中在文件数据与内存数据转换时肯定会涉及到编码的,其实不论java语言了其他语言都有的,只不过这些语言的通常做法都是使用默认的编码方式,但是我们必须要明白这其中的原理,不然以后出现一点乱码都将会是头痛的问题!!!

